Modelagem de dados com DynamoDB

André Werlang
@awerlang
The Developer's Conference 2017 - Porto Alegre
Do you know DynamoDB?
Amazon DynamoDB is a fully managed non-relational database service that provides fast and predictable performance with seamless scalability.
Use cases
- Mobile
- Web
- Gaming
- Advertisement
- IoT
Architecture
Latency vs Requests
Partitioning
Avoiding throttling
- Access is evenly spread over key-space
- Cache popular items
- Read/write sharding
- Requests arrive evenly spaced in time
Bursting
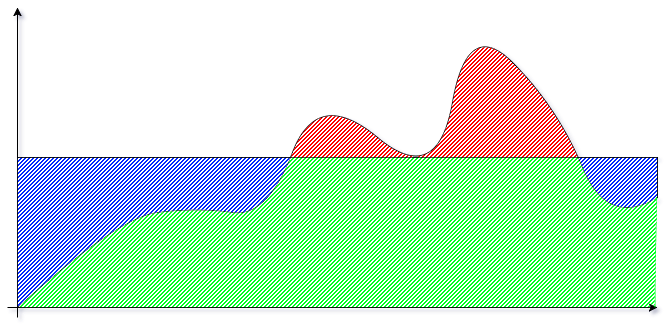
Other features
- Auto scaling
- Metrics, monitoring, alarms
- Triggers & streams (AWS Lambda)
- Time to live attribute
- Atomic updates
- DAX: transparent, in-memory cache
Throughput & costs
- Read Capacity Unit (RCU) = 4 KB
- Write Capacity Unit (WCU) = 1 KB
- Billed by the hour
| RCU | WCU | USD |
|---|---|---|
| 50 | 25 | 3,57 |
| 100 | 50 | 28,55 |
| 2000 | 400 | 549,55 |
* Region South America, monthly price before taxes.
Concepts: Table
| P1 | S1 | string | 145.99 |
| P2 | S1 | string | null | |
| P2 | S2 | string | null | [12, 34] |
| P3 | S1 | string | 45.99 |
* Max item size: 400 KB
Concepts: Indexes
Table
| Sender | Msg Id | Date | Sent To | Body |
Local Secondary Index
| Sender | Date | Msg Id | Sent To |
Global Secondary Index
| Sent To | Date | Msg Id | Sender |
Concepts: Indexes
- Sparse: ignores items missing key attributes
- Supported in Query & Scan operations
- Local
- Synchronous update
- Global
- Eventually consistent, always
Concepts: Data Types
- Simple
- string (except empty string)
- number (stored as text)
- binary
- Other
- boolean
- set (of string, number, binary)
- map
- list (of any)
- null
DynamoDB Math
| 3 KB | 1 RCU, 3 WCU | |||
| 1 KB | 1 RCU, 1 WCU | 1 RCU | ||
| 2 KB | 1 RCU, 2 WCU | |||
Data Operations
Get Item
{
TableName: "Users",
Key: {
id: "user-123"
},
ConsistentRead: false,
}
Data Operations
Scan
{
TableName: "Users",
IndexName: 'ByCountry',
FilterExpression: "country = 'Brazil'",
Limit: 10,
}
Data Operations
Query
{
TableName: "Messages",
KeyConditionExpression: "userId = 'user-123' and date > '2017-10-15'",
}
Data Operations
Put Item
{
TableName: "Messages",
Item: {
id: "msg-1",
userId: "user-123",
date: "2017-11-07",
subject: "TDC is about to start...",
body: "...",
},
}
Data Operations
Update Item
{
TableName: "Game",
Key: {
id: 'game-123',
},
UpdateExpression: "
set topLeft = 'O',
version = version + 1,
moves = list_append(moves, ['Alice']),
metadata = if_not_exists(metadata, {})
remove pending
add 'pending' to gameState
",
ConditionExpression: "version = 1",
}
Data Operations
Delete Item
{
TableName: "Messages",
Key: {
id: 'msg-123',
},
}
Update Expressions (SET)
- Functions: if_not_exists, and list_append
Update Conditionals
- Functions: ATTRIBUTE_EXIST, CONTAINS, and BEGINS_WITH
- Comparison: =, <>, <, >, <=, >=, BETWEEN, and IN
- Logical: NOT, AND, and OR
Modeling with DynamoDB
- How often data is read?
- How big are items?
- How data is retrieved?
- What attributes change on items?
- Any popular items?
1:N relations - I
Conference Track - talks as lists
| TrackID | Title | Talks | ||||||||||||
| 1 | NoSQL |
|
Writes are expensive and non-atomic.
1:N relations - II
Conference Track - talks as maps
| TrackID | Title | Talks | ||||||||||||
| 1 | NoSQL |
|
Writes are atomic. Writes are still expensive.
1:N relations - III
Conference Track - talks as separate table
| TrackID | ID | Title | Speaker |
| 1 | 1 | Talk 1 | Speaker 1 |
| 1 | 2 | Talk 2 | Speaker 2 |
| 1 | 3 | Talk 3 | Speaker 3 |
Writes are cheap.
1:N relations - IV
Conference Track - composite sort keys
| TrackID | ID | Title | Speaker | Date |
| 1 | track | NoSQL | 20171109 | |
| 1 | talk:1 | Talk 1 | Speaker | |
| 1 | talk:2 | Talk 2 | Speaker | |
| 1 | talk:3 | Talk 3 | Speaker |
Reads are flexible.
Large Items - Overflow table
| UserId | MsgId | Subject | Body | Parts |
| 1 | 10 | URGENT | part 1/3 | 3 |
| 1 | 25 | HELP | part 1/1 | 1 |
| MsgId | Part # | Body | |
| 10 | 1 | part 2/3 | |
| 10 | 2 | part 3/3 | |
Good for read-only views.
Time Series
Events_2017_11
| Date | Id | ... | 1000 RCUs / 1000 WCUs | |
Events_2017_10
| Date | Id | ... | 100 RCUs / 100 WCUs | |
Events_2017_09
| Date | Id | ... | 10 RCUs / 10 WCUs | |
Time Series
Events
| Id | Bucket (1..N) | Date | ... | 1000 RCUs / 1000 WCUs | |
EventsByBucketIndex (GSI)
| Bucket | Date | Id | 10 RCUs / 10 WCUs | |
Scatter / Gather
Are you missing...
- Transactions?
- Joins?
- Ad hoc queries?
- Geospatial data?
- Backups?
Wait...
Did you say NO BACKUPS?

 Source:
https://youtu.be/w-QLCWHj5XM?t=94
Source:
https://youtu.be/w-QLCWHj5XM?t=94
Top 3 reasons
- Low latency and predictability
- Scalability
- Cost effective
- Bonus: fully managed
Next steps
- Download DynamoDB Local at http://docs.aws.amazon.com/amazondynamodb/latest/developerguide/DynamoDBLocal.html
- Run and navigate to http://localhost:8000/shell/
- Type
tutorial.start()and press ENTER - Follow steps
References
- https://aws.amazon.com/dynamodb/